


На фото: серверные GPU-ускорители NVIDIA поколения Hopper, используемые в AI-дата-центрах.
Если коротко: H200 — это развитие H100, в котором основной упор сделан на память и пропускную способность.
И именно это отличие становится критичным в современных AI-проектах — особенно в задачах с большими языковыми моделями, RAG и длинным контекстом.
На практике выбор между H100 и H200 — это не выбор “старого и нового”, а выбор инструмента под конкретный тип нагрузки.
Архитектура и общее между H100 и H200
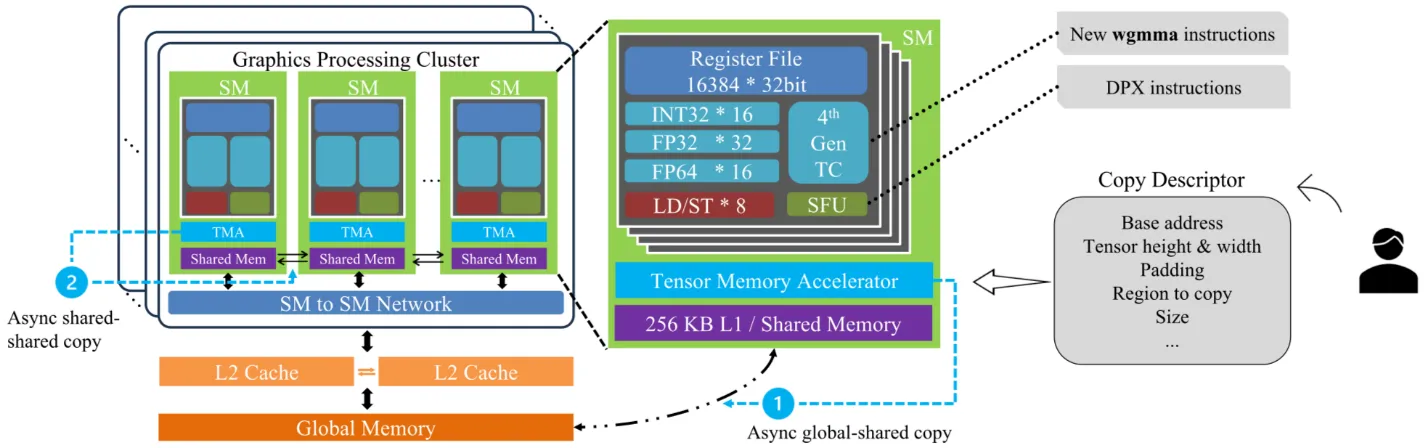
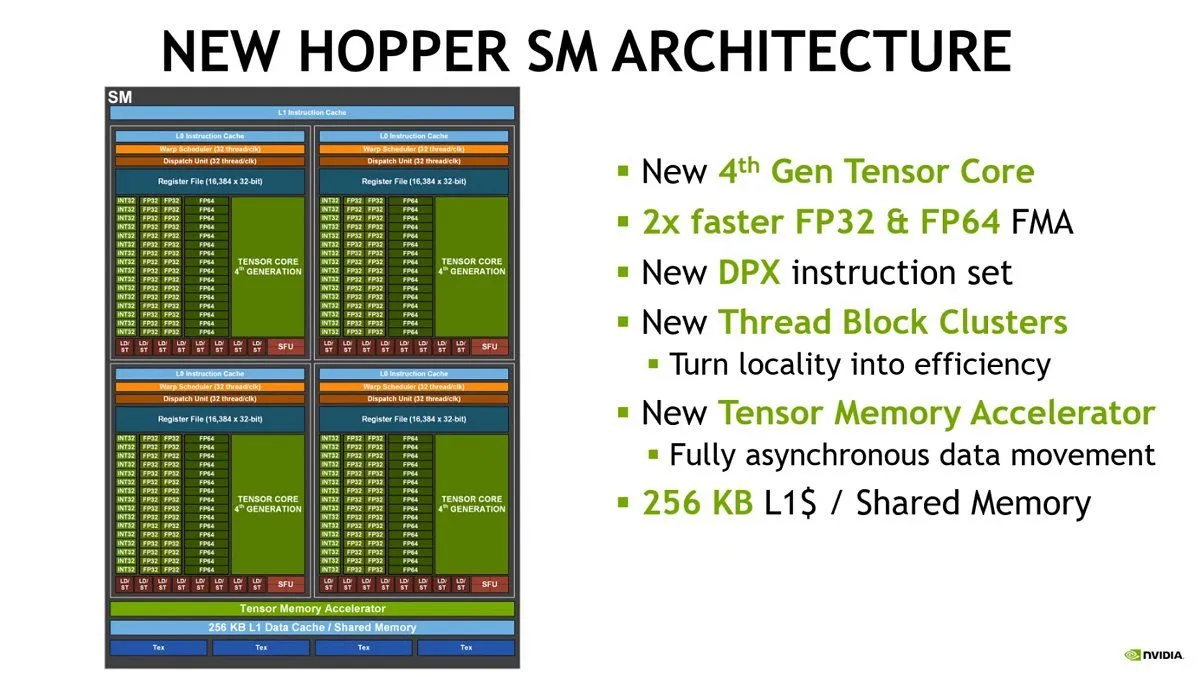
На фото: архитектура Hopper и тензорные ядра NVIDIA, лежащие в основе H100 и H200.
Обе модели:
- построены на архитектуре Hopper
- используют тензорные ядра для AI и HPC
- поддерживают современный программный стек NVIDIA
- применяются в серверных и кластерных конфигурациях
👉 Ключевая разница между ними — не в вычислительных блоках, а в работе с памятью.
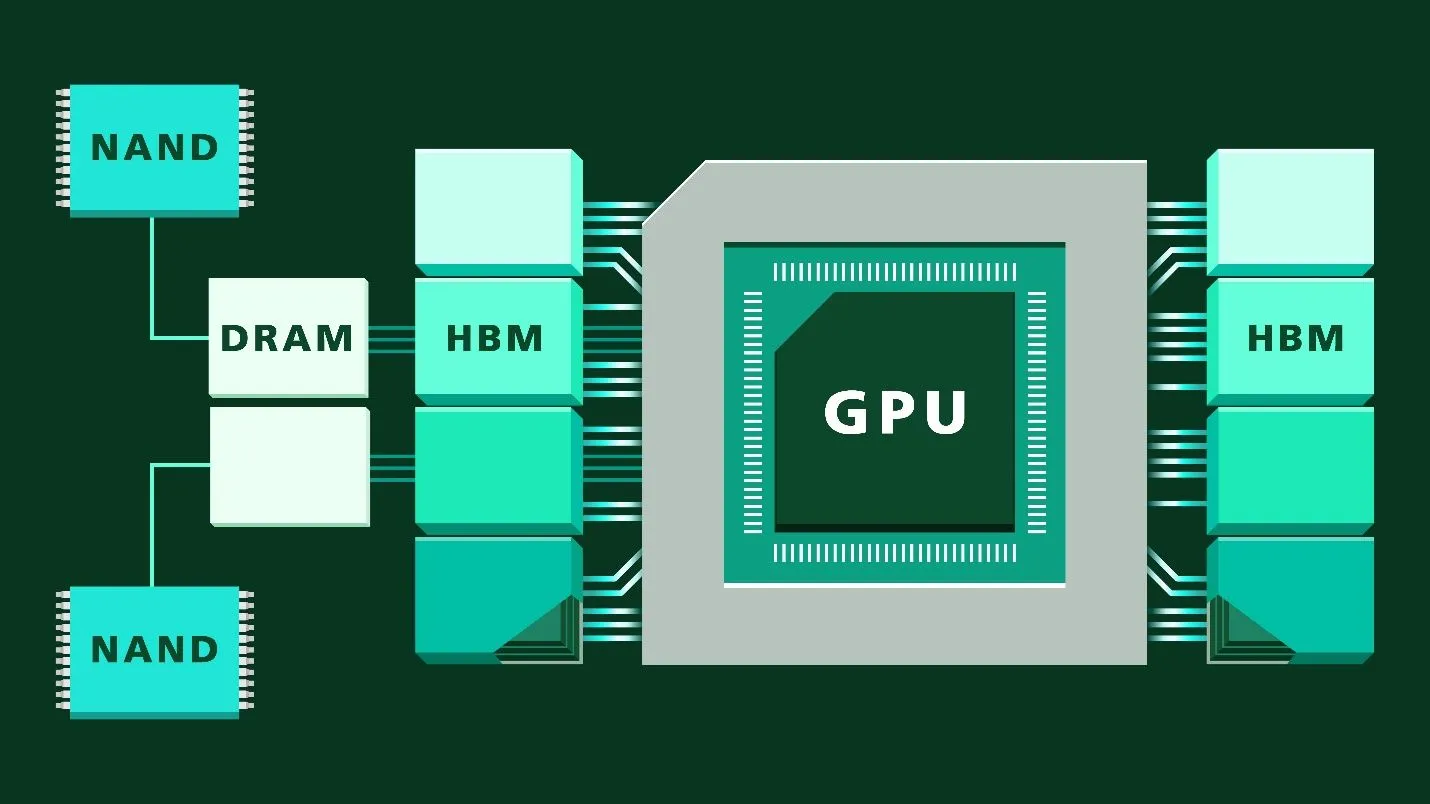
Ключевое отличие: память и пропускная способность

На фото: высокоскоростная HBM-память, определяющая эффективность работы AI-ускорителей.
NVIDIA H100
- память HBM3
- типовые конфигурации — 80 GB
- отлично справляется с обучением и инференсом, пока задача не упирается в память
NVIDIA H200
- память HBM3e
- увеличенный объём — 141 GB
- заметно более высокая пропускная способность памяти
На практике это означает:
- H100 чаще ограничен вычислениями
- H200 чаще упирается в модель, а не в железо
Именно поэтому H200 стал особенно востребован в задачах инференса больших LLM.
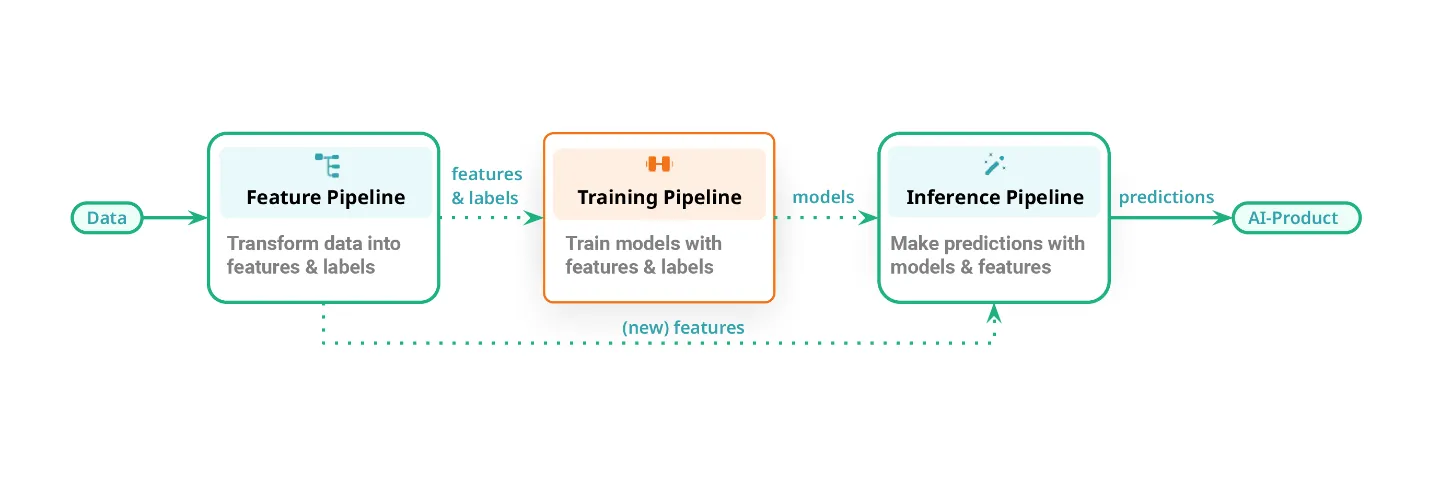
Форм-факторы и способы интеграции


На фото: варианты интеграции GPU — PCIe, NVLink и NVSwitch.
Важно понимать:
PCIe, NVL, SXM, DGX — это не разные видеокарты, а разные способы их использования.
- PCIe — стандартная установка в сервер, проще всего внедрять
- NVL — оптимизация под multi-GPU инференс и большие модели
- SXM — модульный формат с максимальной связностью GPU
- DGX — готовая платформа «под ключ»
Ошибки на этом этапе стоят дорого — часто выбирают мощный GPU, но не тот форм-фактор.
Где чаще выбирают NVIDIA H100 (реальная практика)

На фото: GPU-кластер на базе H100 для обучения нейросетей.
Типовые сценарии H100:
- обучение больших моделей
- регулярный fine-tuning
- HPC и инженерные расчёты
- проекты, где важна стабильность и масштабирование
Практический пример из проектов
Команды, которые обучают собственные модели или часто дообучают LLM под доменные данные, выбирают H100 за:
- предсказуемость производительности
- удобство масштабирования
- зрелую экосистему и инфраструктуру
👉 H100 — универсальный и понятный инструмент для обучения.
Где выигрывает NVIDIA H200 (реальная практика)

На фото: инфраструктура для инференса больших языковых моделей и RAG-систем.
Типовые сценарии H200:
- инференс LLM с длинным контекстом
- RAG-системы с большими векторами
- AI-ассистенты с высокой параллельной нагрузкой
- API-сервисы с требованиями к задержке
Практический эффект в проектах:
- модель целиком помещается в память одного GPU
- снижается необходимость в sharding
- уменьшаются задержки
- часто требуется меньше ускорителей на ту же нагрузку
👉 H200 — это про эффективность inference, а не “больше TFLOPS”.
Обучение vs инференс — ключевая развилка
На фото: различия между обучением и инференсом нейросетей.
Практическое правило:
- Training → чаще H100
- Inference → чаще H200
Одна из самых частых ошибок:
- покупать H200 для задач, где H100 дешевле и эффективнее
- или брать H100, когда проект уже упирается в память и latency
Экономика проекта: почему цена GPU — не главное
На фото: расчёт экономики AI-инфраструктуры и оптимизация затрат.
На практике считают не цену карты, а:
- стоимость одного запроса
- стоимость одного токена
- плотность нагрузки на GPU
- количество серверов и стоек
Часто выходит так:
- H100 дешевле на входе
- H200 дешевле на результат, особенно в inference-проектах
Как мы подходим к выбору в GIS Server

На фото: проектирование AI-инфраструктуры и подбор GPU под задачу.
Мы начинаем не с модели GPU, а с вопросов:
- обучение или инференс
- размер модели и контекст
- пиковая параллельная нагрузка
- планы масштабирования
- сервер, узел или кластер
В большинстве случаев ответ H100 или H200 становится очевидным уже после этого диалога.
Итоговое сравнение: что выбрать


На фото: современный AI-дата-центр с GPU-ускорителями.
Выбирайте NVIDIA H100, если:
- основной фокус — обучение
- важна зрелость и универсальность
- инфраструктура уже построена под H100
Выбирайте NVIDIA H200, если:
- основной фокус — инференс
- вы упираетесь в память и пропускную способность
- работаете с большими LLM и RAG
Вывод
H100 и H200 — это два разных инструмента под разные задачи, а не конкуренты в лоб.
Правильный выбор:
- снижает бюджет
- ускоряет запуск
- повышает стабильность AI-сервисов
Именно поэтому в реальных проектах мы всегда смотрим на нагрузку и экономику, а не на сухие спецификации.
|
Параметр |
NVIDIA H100 |
NVIDIA H200 |
|---|---|---|
|
Поколение |
Hopper |
Hopper (расширенная версия) |
|
Архитектура |
NVIDIA Hopper |
NVIDIA Hopper |
|
Основной фокус |
Универсальный AI: training + inference |
Memory-heavy AI: inference, LLM, RAG |
|
Тип памяти |
HBM3 |
HBM3e |
|
Объём памяти (типично) |
80 GB (есть варианты 94 GB NVL) |
141 GB |
|
Пропускная способность памяти |
Высокая |
Существенно выше, чем у H100 |
|
Работа с длинным контекстом |
Ограничена объёмом памяти |
Заметно эффективнее |
|
Inference больших LLM |
Хорошо |
Лучше (меньше шардирования, ниже latency) |
|
Обучение (training) |
Отлично подходит |
Подходит, но не всегда оправдан |
|
Fine-tuning моделей |
Да |
Да |
|
RAG-системы |
Подходит |
Оптимальный вариант |
|
HPC и инженерные расчёты |
Широко используется |
Эффективен для memory-bound задач |
|
Типичные форм-факторы |
PCIe, SXM, HGX, DGX |
PCIe, NVL, HGX, DGX |
|
Масштабирование на 4–8 GPU |
Отлично (SXM / HGX / DGX) |
Отлично (HGX / DGX) |
|
Простота внедрения |
Выше |
Чуть сложнее (из-за требований к памяти/платформе) |
|
Экосистема и зрелость |
Максимальная |
Новее, но совместима |
|
Экономика |
Дешевле на входе |
Часто дешевле на результат (inference) |
|
Когда выбирать |
Training, универсальные задачи |
Inference, большие модели, длинный контекст |
FAQ — NVIDIA H100 и H200: ответы на частые вопросы
❓ В чём основная разница между NVIDIA H100 и H200?
Основная разница между NVIDIA H100 и H200 — в памяти.
H200 использует HBM3e с увеличенным объёмом (141 GB) и более высокой пропускной способностью, поэтому лучше подходит для inference больших языковых моделей и RAG-систем. H100 универсальнее и чаще используется для обучения моделей.
❓ Что лучше выбрать для LLM и генеративного ИИ — H100 или H200?
Для инференса LLM, длинного контекста и RAG чаще выбирают NVIDIA H200.
Для обучения и fine-tuning моделей чаще выбирают NVIDIA H100, особенно в SXM/HGX/DGX-конфигурациях.
❓ Подходит ли NVIDIA H200 для обучения нейросетей?
Да, H200 подходит для обучения, но его потенциал раскрывается именно в memory-heavy задачах.
Если обучение не упирается в память, H100 часто оказывается экономически целесообразнее.
❓ Можно ли заменить H100 на H200 без изменения инфраструктуры?
Не всегда.
H200 предъявляет более высокие требования к серверу, питанию и охлаждению. Перед заменой важно проверить совместимость платформы и целесообразность с точки зрения нагрузки.
❓ Что выгоднее для бизнеса: H100 или H200?
Зависит от задачи:
- H100 дешевле на старте и универсальнее
- H200 часто дешевле на результат (стоимость inference, токена или запроса)
Для AI-сервисов и API-нагрузок H200 нередко снижает итоговые затраты.
❓ Есть ли смысл покупать H200 для небольшого AI-проекта?
Если проект небольшой и не упирается в память, H100 обычно достаточно.
H200 оправдан, когда:
- используется большая модель
- требуется длинный контекст
- высокая параллельная нагрузка
❓ Какие форм-факторы доступны для H100 и H200?
Обе модели доступны в нескольких вариантах:
- PCIe — для стандартных серверов
- NVL — оптимизация под inference и multi-GPU
- SXM / HGX — для кластеров и обучения
- DGX — готовая AI-платформа
Выбор форм-фактора так же важен, как и выбор самой модели GPU.
❓ Можно ли использовать H100 и H200 в одном кластере?
Да, такие конфигурации возможны, но требуют корректной архитектуры и настройки.
На практике чаще разделяют:
- H100 — под обучение
- H200 — под инференс
❓ Какой GPU чаще выбирают компании в России и СНГ?
В реальных проектах:
- H100 чаще выбирают для обучения и универсальных AI-кластеров
- H200 — для inference-платформ, AI-сервисов и корпоративных ассистентов
Выбор обычно зависит от доступности инфраструктуры и типа нагрузки.
❓ Что лучше для RAG-систем и работы с векторными базами?
Для RAG-систем чаще выбирают NVIDIA H200, так как:
- больше памяти
- выше пропускная способность
- меньше необходимости в шардировании
❓ Как понять, что мне действительно нужен H200, а не H100?
Если у вас:
- модель не помещается в память H100
- растёт latency на inference
- увеличивается количество GPU без роста эффективности
— это прямые признаки, что стоит рассматривать H200.
❓ Помогает ли GIS Server с выбором между H100 и H200?
Да. Мы подбираем GPU не «по прайсу», а по задаче:
- training или inference
- размер модели и контекст
- нагрузка и планы масштабирования
- сервер или кластер
Это позволяет избежать переплаты и ошибок при закупке.




