


На фото: ускоритель NVIDIA H200 — серверный GPU для AI и дата-центров.
Если вы рассматриваете покупку NVIDIA H200, то почти наверняка уже видели разные обозначения:
PCIe, NVL, SXM, HGX, DGX.
Создаётся ощущение, что это разные видеокарты — но на самом деле это разные форм-факторы и способы использования одного ускорителя.
В этой статье разберём:
- что такое NVIDIA H200 и чем он отличается от H100
- что означают PCIe, NVL, SXM и DGX
- для каких задач подходит каждая модификация
- как выбрать H200 под конкретный AI-проект
Что такое NVIDIA H200 (коротко)


На фото: архитектура Hopper и плата NVIDIA H200 с памятью HBM3e.
NVIDIA H200 — это развитие архитектуры Hopper, ориентированное на работу с большими моделями и объёмами данных.
Ключевое отличие H200 от H100 — переход на память HBM3e и увеличение её пропускной способности.
Основные характеристики H200:
- архитектура: Hopper
- память: 141 GB HBM3e
- существенно более высокая пропускная способность памяти по сравнению с H100
- оптимизация под LLM, RAG, inference и training больших моделей
Важно:
H200 — это не «новая карта для всех подряд». Она создана для задач, где узким местом становится память, а не чистая вычислительная мощность.
PCIe, NVL, SXM, DGX — в чём вообще разница
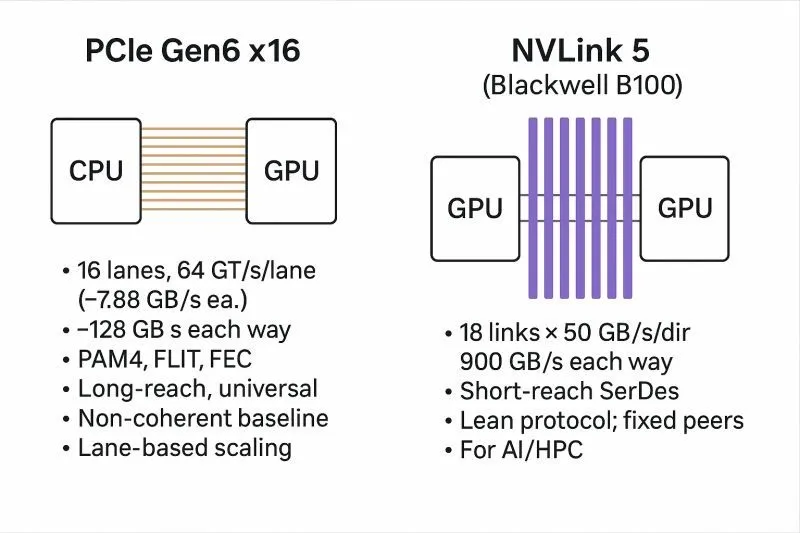
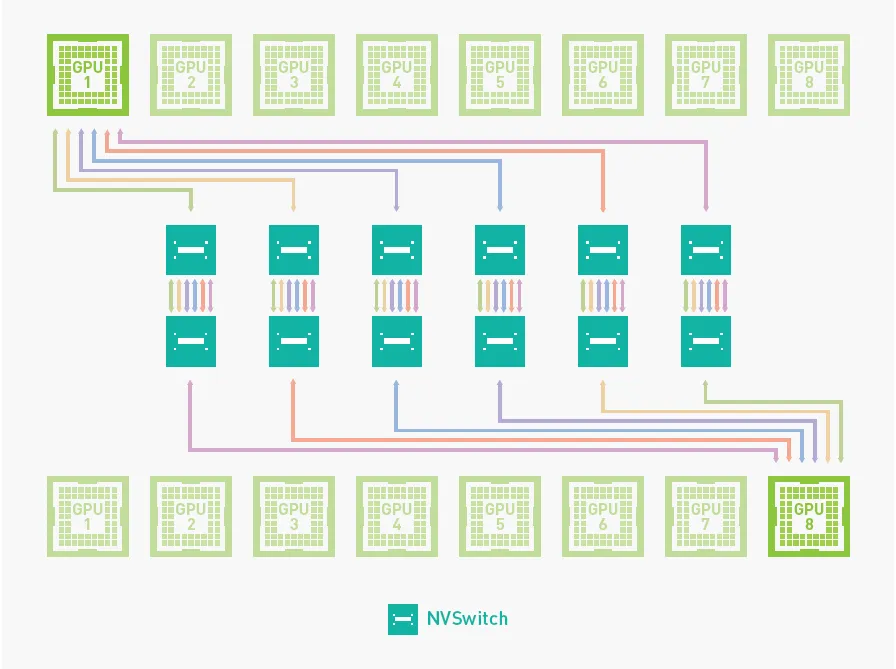
На фото: схемы соединения GPU через PCIe, NVLink и NVSwitch.
Проще всего представить так:
H200 — это “двигатель”, а PCIe / NVL / SXM / DGX — это “как этот двигатель встроен в систему”.
- PCIe — стандартная серверная карта в PCIe-слоте
- NVL — вариант для более эффективной multi-GPU работы и инференса
- SXM — модуль для специализированных платформ с NVLink/NVSwitch
- DGX — готовая AI-платформа «под ключ»
H200 PCIe — самый универсальный вариант



На фото: NVIDIA H200 PCIe, установленная в сервер.
Что означает PCIe
H200 PCIe — это серверный ускоритель в стандартном форм-факторе PCIe.
Он совместим с большинством современных серверов при соблюдении требований к питанию и охлаждению.
Для каких задач подходит
- инференс LLM и RAG-систем
- AI-сервисы в продакшене
- 1–2 GPU на сервер
- проекты, где важны скорость внедрения и простота инфраструктуры
Что важно учитывать
- межGPU-обмен ограничен PCIe
- для масштабного обучения моделей менее эффективен, чем SXM
Кому подойдёт
✔ продуктовым AI-командам
✔ компаниям, запускающим inference-сервисы
✔ тем, кому нужен быстрый старт без сложной платформы
H200 NVL — для высоконагруженного инференса



На фото: конфигурация NVIDIA H200 NVL с высокоскоростным обменом между GPU.
Что означает NVL
H200 NVL — вариант, оптимизированный под multi-GPU inference, где критичны:
- объём памяти
- скорость обмена между ускорителями
- стабильная работа под нагрузкой
Когда NVL предпочтительнее PCIe
- инференс больших LLM
- обработка длинного контекста
- высокая параллельная нагрузка
Нюансы
NVL раскрывается именно в задачах инференса.
Для обучения больших моделей SXM-архитектура остаётся эффективнее.
H200 SXM — максимум эффективности для обучения



На фото: модуль NVIDIA H200 SXM и платформа HGX с NVSwitch.
Что означает SXM
SXM — модульный формат H200 для специализированных платформ HGX/DGX.
Он обеспечивает максимальную пропускную способность между GPU за счёт NVLink и NVSwitch.
Для каких задач подходит
- обучение крупных LLM
- fine-tuning больших моделей
- HPC и распределённые вычисления
Минусы
- требуется специализированный сервер
- выше требования к охлаждению и питанию
- избыточен для простых inference-задач
DGX H200 — готовая AI-платформа



На фото: сервер NVIDIA DGX H200 с восемью ускорителями.
Что такое DGX H200
DGX H200 — это законченная AI-платформа, включающая:
- 8 × NVIDIA H200
- NVSwitch-архитектуру
- сервер, сеть, охлаждение и ПО
Для кого DGX — оптимален
- enterprise-проекты
- AI-лаборатории
- компании, где важна предсказуемость и быстрый запуск
Сравнение всех модификаций H200

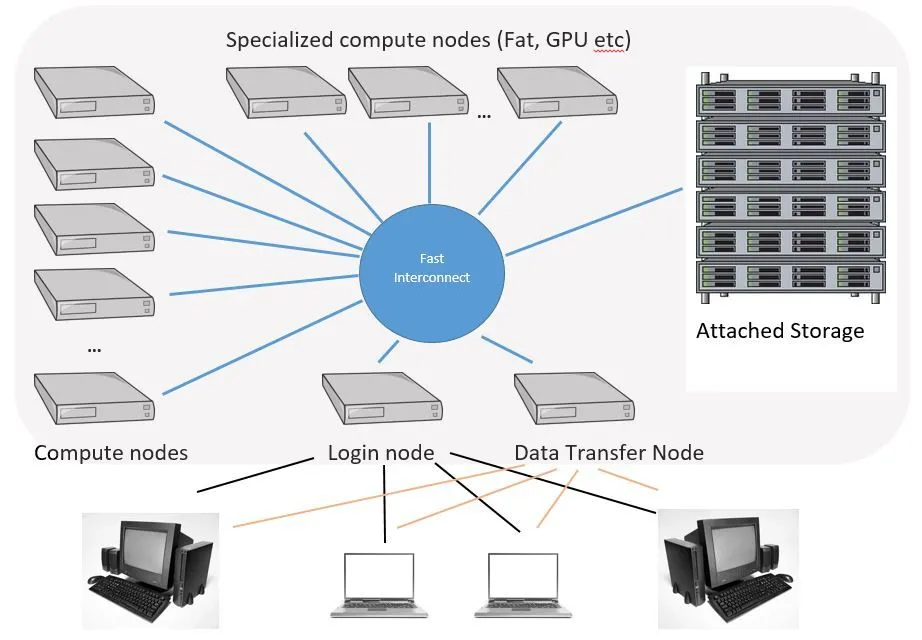
На фото: GPU-кластер в дата-центре для AI-нагрузок.
|
Модификация |
Где используется |
Сильная сторона |
Типичные задачи |
|---|---|---|---|
|
H200 PCIe |
стандартные серверы |
простота внедрения |
inference, AI-сервисы |
|
H200 NVL |
multi-GPU inference |
память и обмен |
inference больших LLM |
|
H200 SXM |
HGX/DGX |
межGPU-связь |
обучение LLM, HPC |
|
DGX H200 |
готовая платформа |
минимум рисков |
enterprise AI |
Как выбрать H200 под свою задачу

На фото: проектирование AI-инфраструктуры в дата-центре.
Практический ориентир:
- Inference и продакшн-AI → H200 PCIe или NVL
- Большие модели и длинный контекст → H200 NVL
- Обучение и масштабирование → H200 SXM
- Корпоративная платформа без интеграционных рисков → DGX H200
Вывод

На фото: современный дата-центр с AI-инфраструктурой.
NVIDIA H200 — это ускоритель для задач, где критична память и пропускная способность.
PCIe, NVL, SXM и DGX — это не разные карты, а разные способы использовать один и тот же GPU.
Правильный выбор форм-фактора:
- снижает бюджет
- ускоряет запуск
- повышает эффективность проекта
FAQ: NVIDIA H200

На фото: серверная эксплуатация GPU-ускорителей.
FAQ: NVIDIA H200 — PCIe, NVL, SXM и DGX
❓ Что означают PCIe, NVL, SXM и DGX у NVIDIA H200?
Это не разные видеокарты, а разные способы подключения и использования одной и той же GPU NVIDIA H200.
Они отличаются масштабируемостью, скоростью обмена данными между GPU и уровнем интеграции.
❓ В чём разница между H200 PCIe и H200 NVL?
H200 PCIe подключается к серверу через стандартный PCIe-слот и подходит для 1–2 GPU.
H200 NVL использует NVLink, благодаря чему несколько GPU могут быстрее обмениваться данными и работать эффективнее в AI-сервисах.
❓ Что лучше выбрать: H200 PCIe или H200 NVL?
Если нужен inference или AI-сервис с 1–2 GPU, лучше подойдёт PCIe.
Если планируется 2–4 GPU и высокая нагрузка, лучше выбрать NVL из-за более быстрого взаимодействия между видеокартами.
❓ Чем H200 SXM отличается от PCIe и NVL?
H200 SXM — это модуль для специализированных серверов с NVLink и NVSwitch.
Он обеспечивает максимальную скорость обмена между GPU и используется для обучения больших нейросетей и LLM.
❓ Для каких задач подходит H200 SXM?
H200 SXM оптимальна для:
- обучения больших языковых моделей
- моделей 70B+ параметров
- HPC и научных вычислений
- многопроцессорных AI-кластеров
❓ Что такое DGX H200 и чем он отличается от отдельной GPU?
DGX H200 — это готовая AI-платформа, внутри которой уже установлено 8 GPU H200, CPU, сеть и ПО.
В отличие от отдельных GPU, DGX не требует проектирования и интеграции — система готова к работе сразу.
❓ Когда стоит выбирать DGX H200?
DGX H200 выбирают, когда:
- нужен AI-кластер «под ключ»
- важны стабильность и поддержка NVIDIA
- проект корпоративный или государственный
- нет желания заниматься сборкой и интеграцией
❓ Можно ли использовать H200 PCIe для обучения нейросетей?
Технически — да, но это не оптимальный вариант.
Для обучения больших моделей лучше подходят SXM или DGX, так как они обеспечивают более быструю связь между GPU.
❓ Какая модификация H200 лучше для inference?
Для inference чаще всего выбирают:
- H200 PCIe — для небольших и средних нагрузок
- H200 NVL — для высоконагруженных AI-сервисов и LLM с большим контекстом
❓ Все ли модификации H200 имеют одинаковую производительность?
Производительность одного GPU-чипа одинакова, так как используется одна архитектура.
Разница между PCIe, NVL, SXM и DGX — в масштабировании и скорости обмена данными между GPU.
❓ Как выбрать модификацию NVIDIA H200 под свою задачу?
Если кратко:
- PCIe — inference и AI-сервисы
- NVL — масштабируемый продакшн-AI
- SXM — обучение больших моделей
- DGX — готовая enterprise-платформа
Выбор зависит от задач, масштаба и бюджета проекта.
❓ Используется ли NVIDIA H200 в России и СНГ?
Да, NVIDIA H200 используется в корпоративных и дата-центровых проектах.
Чаще всего она поставляется:
- как отдельный GPU
- в составе сервера
- в виде готовой платформы DGX
❓ Какая модификация H200 самая дорогая?
Самые дорогие решения — SXM-кластеры и DGX H200, так как они включают высокоскоростные интерконнекты и готовую инфраструктуру.
PCIe — самый доступный вариант.




