Если вы изучаете видеокарту NVIDIA H200, то почти наверняка сталкивались с непонятными обозначениями: PCIe, NVL, SXM, DGX.
На первый взгляд кажется, что это разные модели видеокарт — но на самом деле это разные способы установки и использования одного и того же GPU.
В этой статье разберёмся:
- что означают эти модификации простыми словами
- чем они реально отличаются
- для каких задач подходит каждая
- и какую H200 стоит выбирать именно вам
Что такое NVIDIA H200 (коротко)
NVIDIA H200 — это дата-центровая GPU для искусственного интеллекта и высокопроизводительных вычислений (HPC).
Её ключевая особенность — 141 ГБ сверхбыстрой памяти HBM3e, что особенно важно для:
- больших языковых моделей (LLM)
- длинного контекста
- обучения и инференса нейросетей
Важно понимать:
во всех модификациях используется один и тот же GPU-чип.
Меняется не «мощность», а способ подключения и масштабирования.
PCIe, NVL, SXM, DGX — в чём вообще разница
Проще всего представить это так:
GPU — это двигатель, а PCIe / NVL / SXM / DGX — это способ, как и куда этот двигатель установлен.
H200 PCIe — самый универсальный вариант



Что означает PCIe
PCIe — это стандартный интерфейс подключения видеокарты к серверу.
Фактически, это серверная версия “обычной” видеокарты, только без вентилятора и с пассивным охлаждением.
Простыми словами
Видеокарта вставляется в сервер → работает → всё просто и понятно.
Для каких задач подходит
- инференс нейросетей
- AI-сервисы в продакшене
- 1–2 GPU на сервер
- проекты, где важна универсальность
Ограничения
- видеокарты медленно обмениваются данными между собой
- не лучший вариант для обучения очень больших моделей
Кому подойдёт
✔ стартапам
✔ AI-сервисам
✔ бизнесу, который запускает AI в продакшене
H200 NVL — усиленный вариант для масштабирования



Что означает NVL
NVL — это видеокарты в формате PCIe, соединённые между собой через NVLink — высокоскоростной мост.
Простыми словами
GPU не просто стоят рядом,
они напрямую и быстро общаются друг с другом.
Для каких задач подходит
- инференс больших моделей
- высоконагруженные AI-сервисы
- 2–4 GPU, работающие как единое целое
Плюсы
- меньше задержек
- выше производительность в multi-GPU
- лучше масштабируемость
Кому подойдёт
✔ продакшн-AI
✔ сервисы с высокой нагрузкой
✔ RAG и LLM с большим контекстом
H200 SXM — максимум производительности


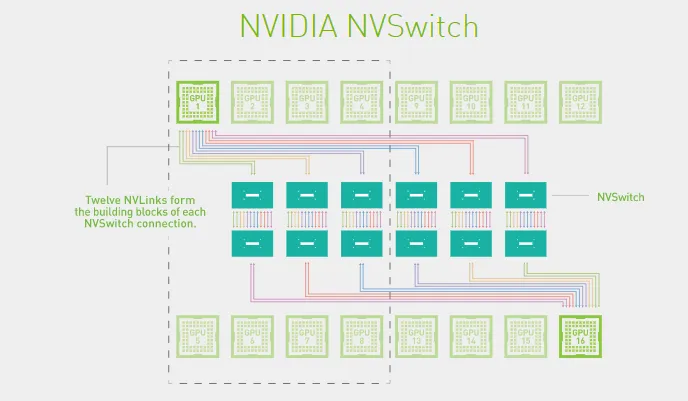
Что означает SXM
SXM — это не видеокарта, а GPU-модуль, который:
- устанавливается в специализированный сервер
- подключается через NVLink и NVSwitch
- работает в плотной связке с другими GPU
Простыми словами
Несколько GPU работают
как одна огромная видеокарта.
Для каких задач подходит
- обучение больших языковых моделей
- модели 70B, 100B+ параметров
- научные и HPC-вычисления
Минусы
- только специализированные серверы
- высокая стоимость
- избыточно для малого бизнеса
Кому подойдёт
✔ AI-лабораториям
✔ крупным компаниям
✔ научным центрам
DGX H200 — готовая AI-платформа



Что такое DGX
DGX — это уже готовый сервер, внутри которого:
- 8 × H200
- CPU
- сеть
- охлаждение
- оптимизированный софт
Простыми словами
Купили → включили → работает.
Для каких задач
- корпоративные AI-платформы
- государственные и научные проекты
- задачи с максимальными требованиями
Кому подойдёт
✔ enterprise-клиентам
✔ тем, кто не хочет заниматься интеграцией
✔ крупным AI-проектам
Сравнение всех модификаций H200
|
Модификация |
Масштаб |
Производительность |
Сложность |
Тип задач |
|---|---|---|---|---|
|
PCIe |
Малый |
Средняя |
Низкая |
Inference, AI-сервисы |
|
NVL |
Средний |
Высокая |
Средняя |
Продакшн-AI |
|
SXM |
Большой |
Максимальная |
Высокая |
Обучение LLM |
|
DGX |
Очень большой |
Максимальная |
Минимальная |
Enterprise AI |
Как выбрать H200 под свою задачу
Если коротко:
- PCIe — если нужен AI в продакшене
- NVL — если важна скорость между GPU
- SXM — если обучаете большие модели
- DGX — если нужен готовый AI-кластер
Вывод
PCIe, NVL, SXM и DGX — это не разные видеокарты, а разные способы использования NVIDIA H200.
Выбор зависит не от того, «что лучше», а от того, какую задачу вы решаете.
Если вы только изучаете рынок — эта статья поможет разобраться.
Если вы уже подбираете конфигурацию — правильный выбор форм-фактора сэкономит деньги, время и нервы.
FAQ: NVIDIA H200 — PCIe, NVL, SXM и DGX
❓ Что означают PCIe, NVL, SXM и DGX у NVIDIA H200?
Это не разные видеокарты, а разные способы подключения и использования одной и той же GPU NVIDIA H200.
Они отличаются масштабируемостью, скоростью обмена данными между GPU и уровнем интеграции.
❓ В чём разница между H200 PCIe и H200 NVL?
H200 PCIe подключается к серверу через стандартный PCIe-слот и подходит для 1–2 GPU.
H200 NVL использует NVLink, благодаря чему несколько GPU могут быстрее обмениваться данными и работать эффективнее в AI-сервисах.
❓ Что лучше выбрать: H200 PCIe или H200 NVL?
Если нужен inference или AI-сервис с 1–2 GPU, лучше подойдёт PCIe.
Если планируется 2–4 GPU и высокая нагрузка, лучше выбрать NVL из-за более быстрого взаимодействия между видеокартами.
❓ Чем H200 SXM отличается от PCIe и NVL?
H200 SXM — это модуль для специализированных серверов с NVLink и NVSwitch.
Он обеспечивает максимальную скорость обмена между GPU и используется для обучения больших нейросетей и LLM.
❓ Для каких задач подходит H200 SXM?
H200 SXM оптимальна для:
- обучения больших языковых моделей
- моделей 70B+ параметров
- HPC и научных вычислений
- многопроцессорных AI-кластеров
❓ Что такое DGX H200 и чем он отличается от отдельной GPU?
DGX H200 — это готовая AI-платформа, внутри которой уже установлено 8 GPU H200, CPU, сеть и ПО.
В отличие от отдельных GPU, DGX не требует проектирования и интеграции — система готова к работе сразу.
❓ Когда стоит выбирать DGX H200?
DGX H200 выбирают, когда:
- нужен AI-кластер «под ключ»
- важны стабильность и поддержка NVIDIA
- проект корпоративный или государственный
- нет желания заниматься сборкой и интеграцией
❓ Можно ли использовать H200 PCIe для обучения нейросетей?
Технически — да, но это не оптимальный вариант.
Для обучения больших моделей лучше подходят SXM или DGX, так как они обеспечивают более быструю связь между GPU.
❓ Какая модификация H200 лучше для inference?
Для inference чаще всего выбирают:
- H200 PCIe — для небольших и средних нагрузок
- H200 NVL — для высоконагруженных AI-сервисов и LLM с большим контекстом
❓ Все ли модификации H200 имеют одинаковую производительность?
Производительность одного GPU-чипа одинакова, так как используется одна архитектура.
Разница между PCIe, NVL, SXM и DGX — в масштабировании и скорости обмена данными между GPU.
❓ Как выбрать модификацию NVIDIA H200 под свою задачу?
Если кратко:
- PCIe — inference и AI-сервисы
- NVL — масштабируемый продакшн-AI
- SXM — обучение больших моделей
- DGX — готовая enterprise-платформа
Выбор зависит от задач, масштаба и бюджета проекта.
❓ Используется ли NVIDIA H200 в России и СНГ?
Да, NVIDIA H200 используется в корпоративных и дата-центровых проектах.
Чаще всего она поставляется:
- как отдельный GPU
- в составе сервера
- в виде готовой платформы DGX
❓ Какая модификация H200 самая дорогая?
Самые дорогие решения — SXM-кластеры и DGX H200, так как они включают высокоскоростные интерконнекты и готовую инфраструктуру.
PCIe — самый доступный вариант.




